[TIL] Experiments: Increasing accuracy of RNN model
06/16/23
![[TIL] Experiments: Increasing accuracy of RNN model](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1688370487435%2F50f4a716-bf6d-4bb5-b0bc-44afd8e6c97e.png&w=3840&q=75)
I conducted four experiments after creating a normalized dataset, and I found that the accuracy significantly improved. Additionally, I attempted cumulative learning. Here are the details of each experiment:
Experiment 1: Cumulative Learning ❌ with a dataset of around 900 instances
I generated a dataset of around 900 sentence examples based on selected symptoms with levels 1 to 5 using KTAS (Korean Triage and Acuity Scale: Emergency Level Standard) and performed tests.
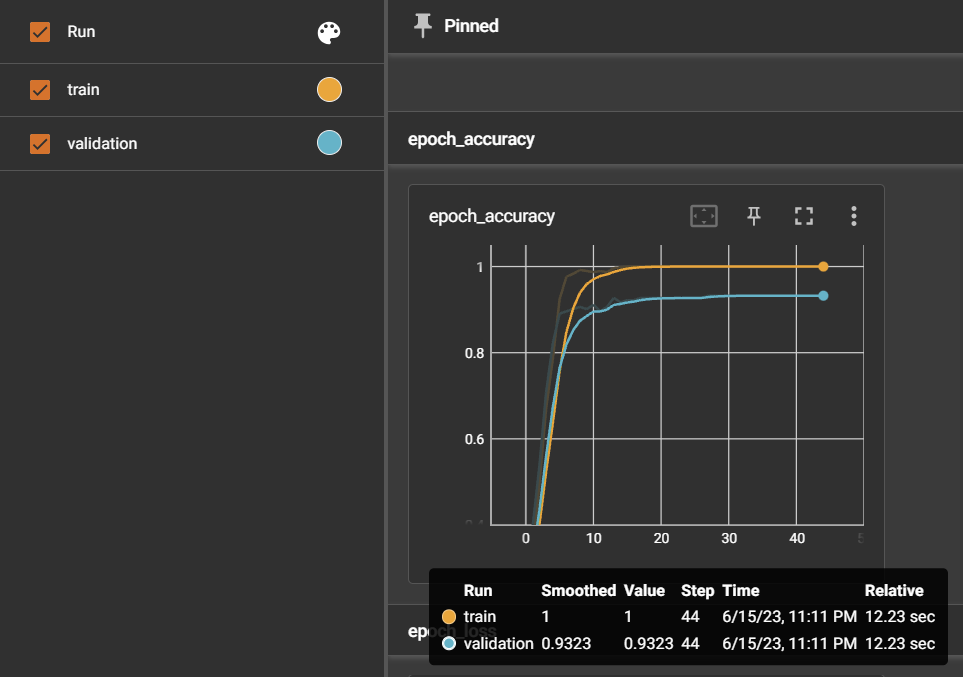
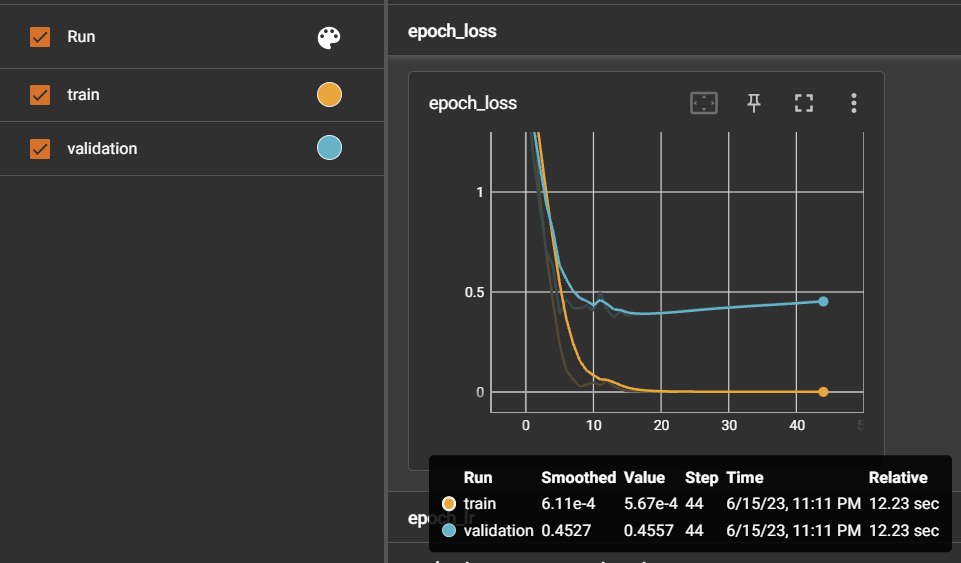

The model accurately predicted the acuity levels only for the symptoms it was trained on (indicated by the blue boxes). However, it struggled to make accurate judgments for sentences containing symptoms that were not included in the training.
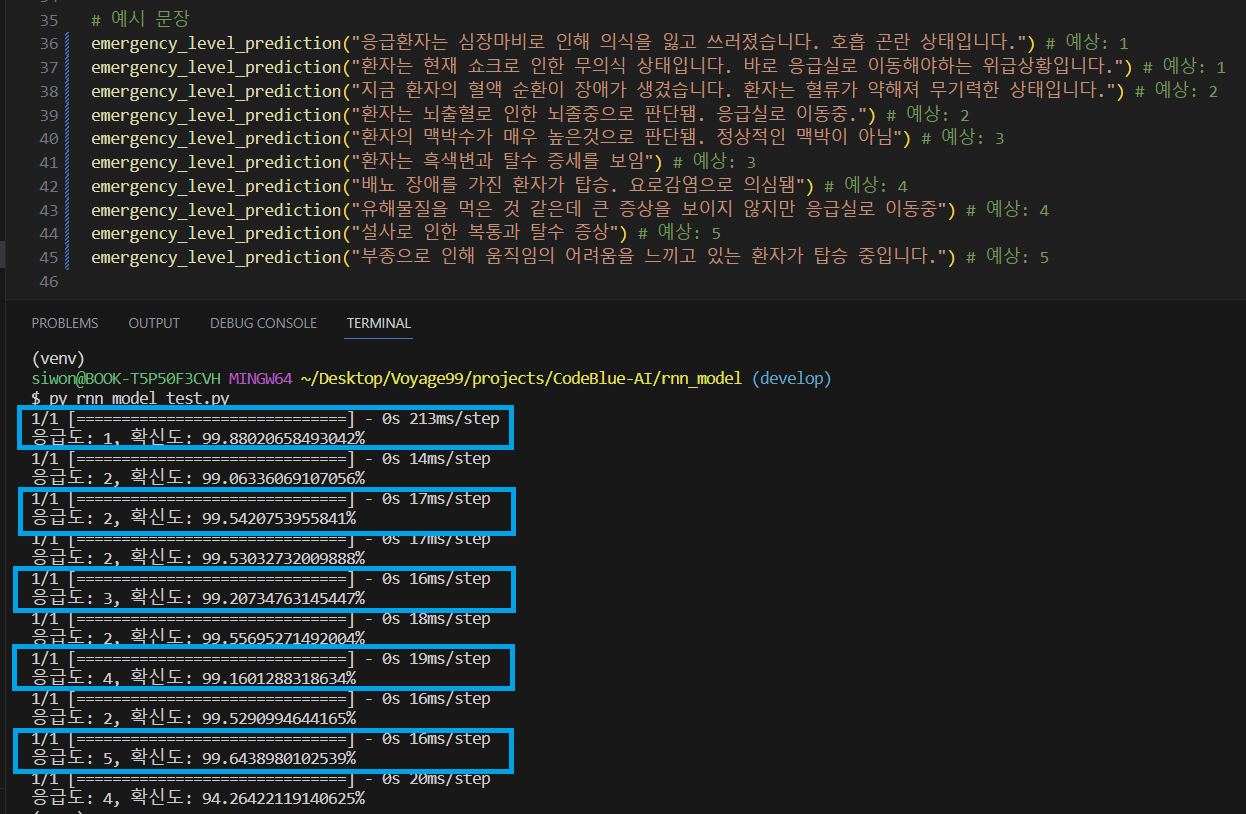
Experiment 2: Cumulative Learning 🔺 with the initial model (dataset of around 900 instances) + cumulative model (new dataset of around 800 instances)
I selected additional symptoms and generated around 800 sentence examples. I then performed cumulative learning on the model trained in Experiment 1.
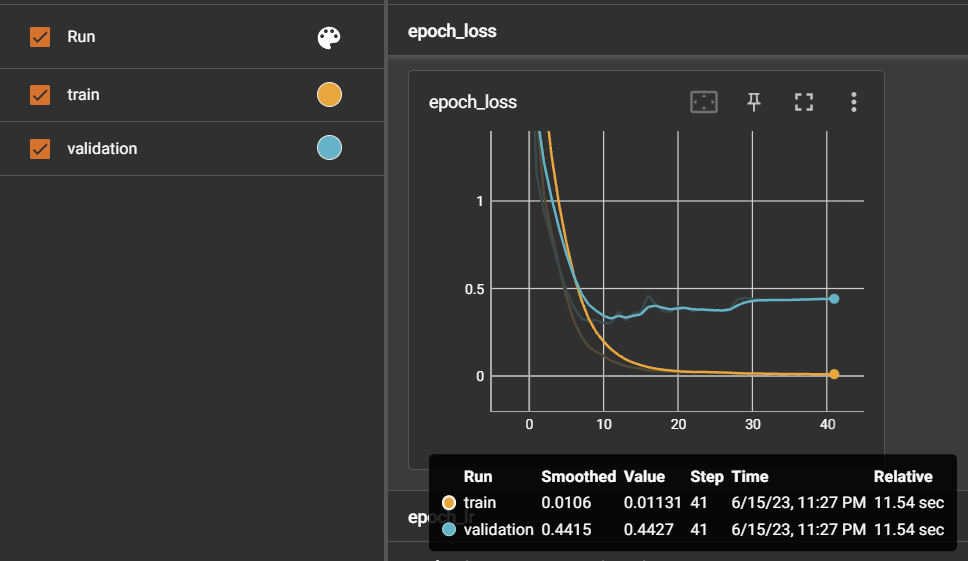

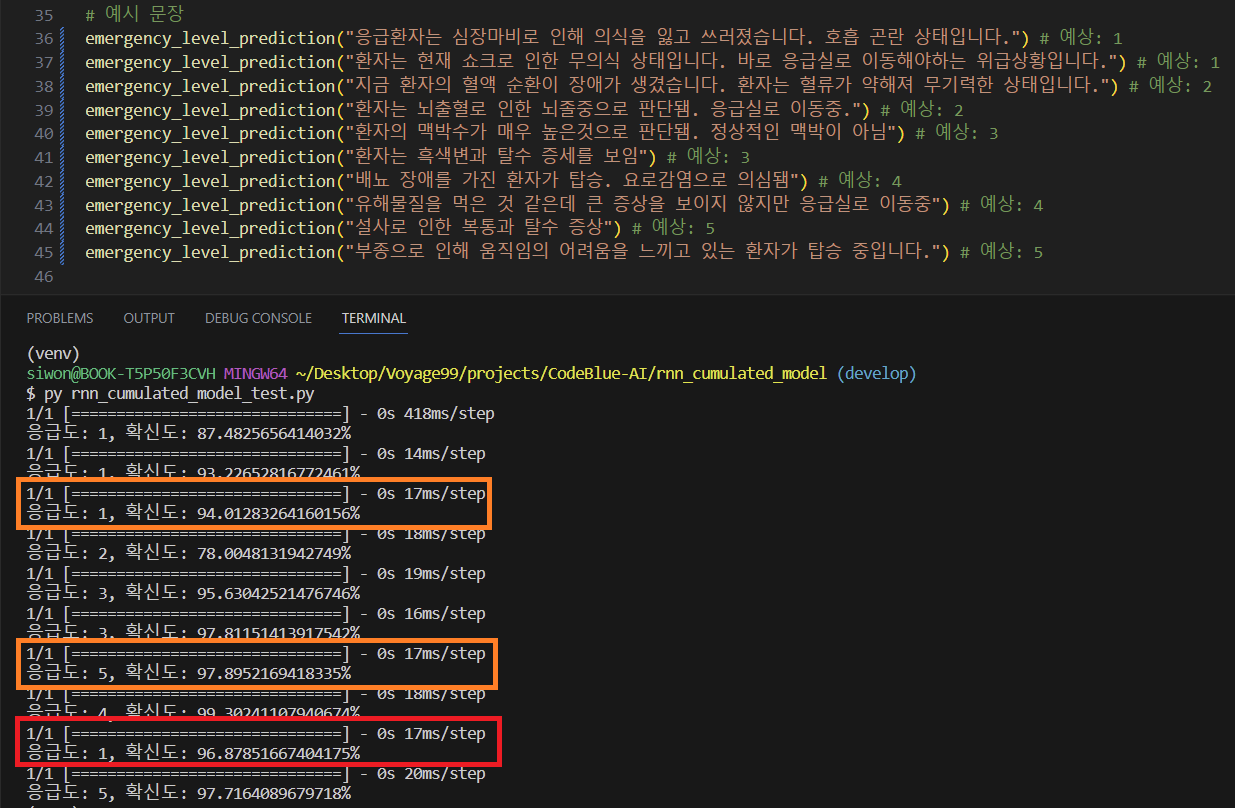
The accuracy decreased compared to the model trained in the first experiment. Despite adding sentences related to symptoms in the additional training dataset, there were still errors in acuity prediction. Particularly, in cases indicated by the red boxes, where an acuity level of 5 was expected but the model predicted 1 with high confidence.
Experiment 3: Cumulative Learning ❌ with a dataset of around 1700 instances
Due to the decreased accuracy and insufficient severity judgment in the model trained in Experiment 2, I created a new dataset of around 1700 sentence examples and trained a new model.
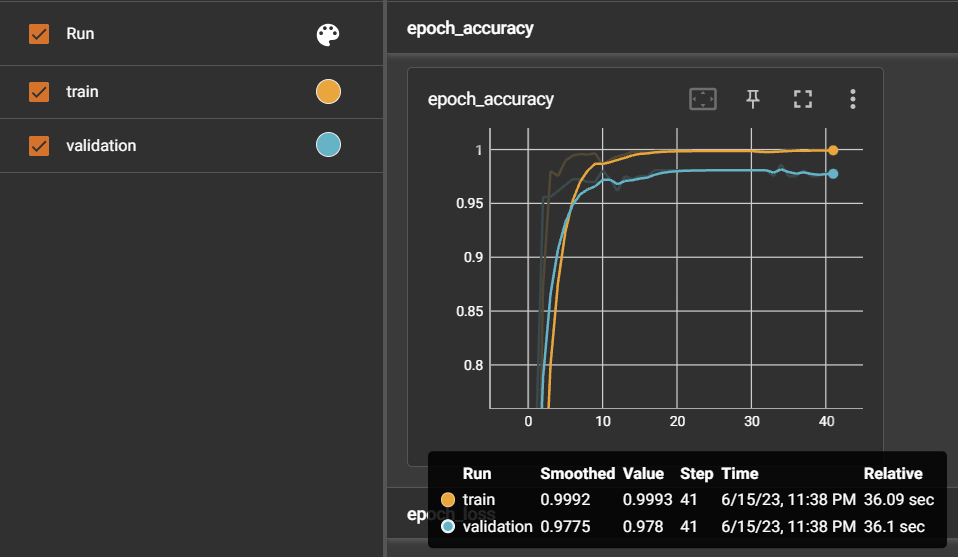
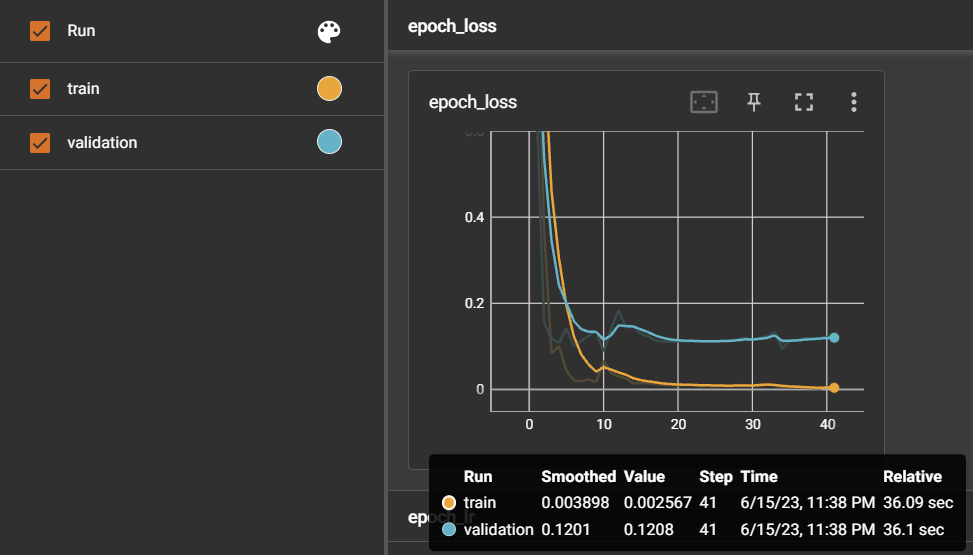

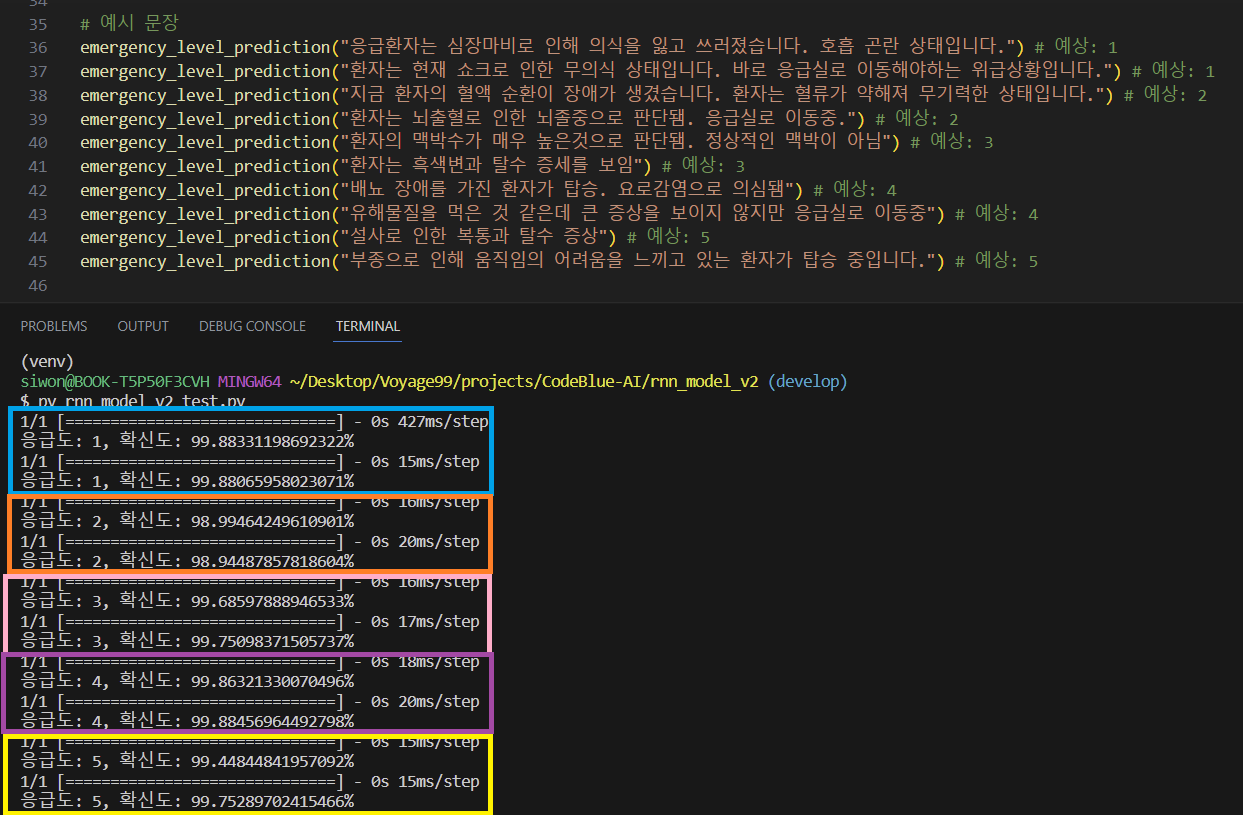
Since this experiment was similar to Experiment 1, the model performed well in predicting acuity for all sentences that included the symptoms it was trained on.
Based on this finding, I conducted Experiment 4.
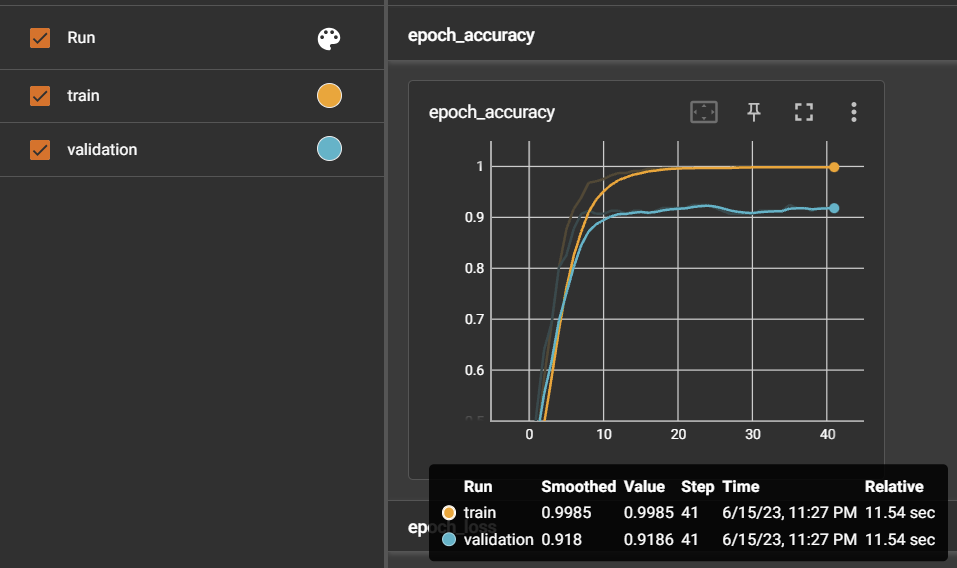
Experiment 4: Cumulative Learning ⭕ with the initial model (dataset of around 900 instances) + cumulative model (new dataset of around 1700 instances)
Considering the improvements made in Experiment 3, where a single model was trained with a dataset of around 1700 instances, I applied a similar approach to Experiment 4. I performed cumulative learning by combining the initial model trained in Experiment 1 (dataset of around 900 instances) with the cumulative model trained on the new dataset of around 1700 instances.
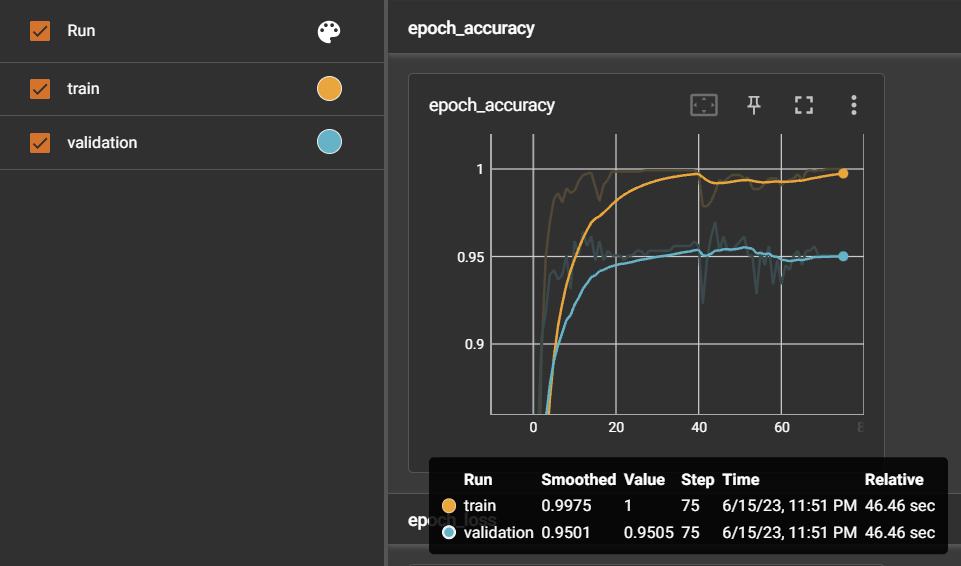
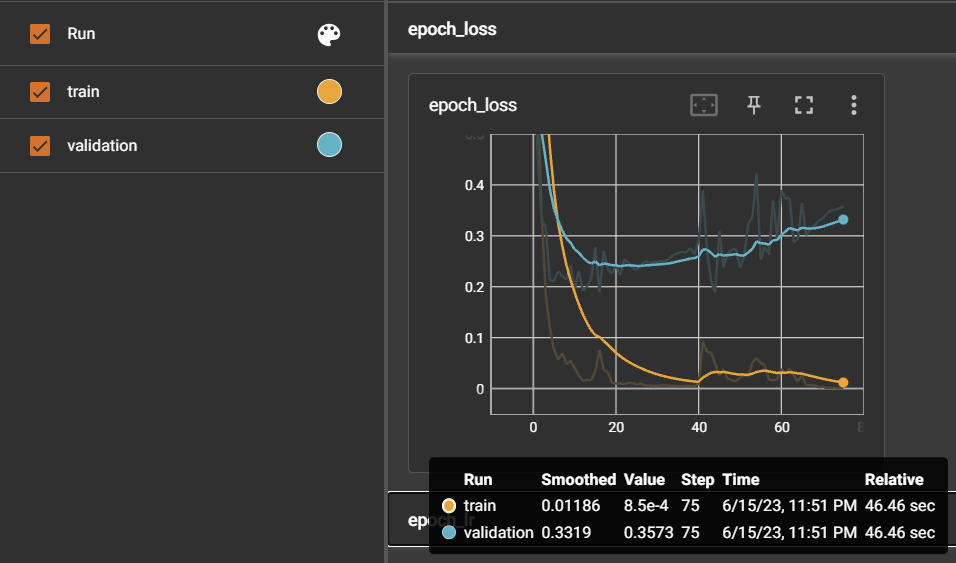

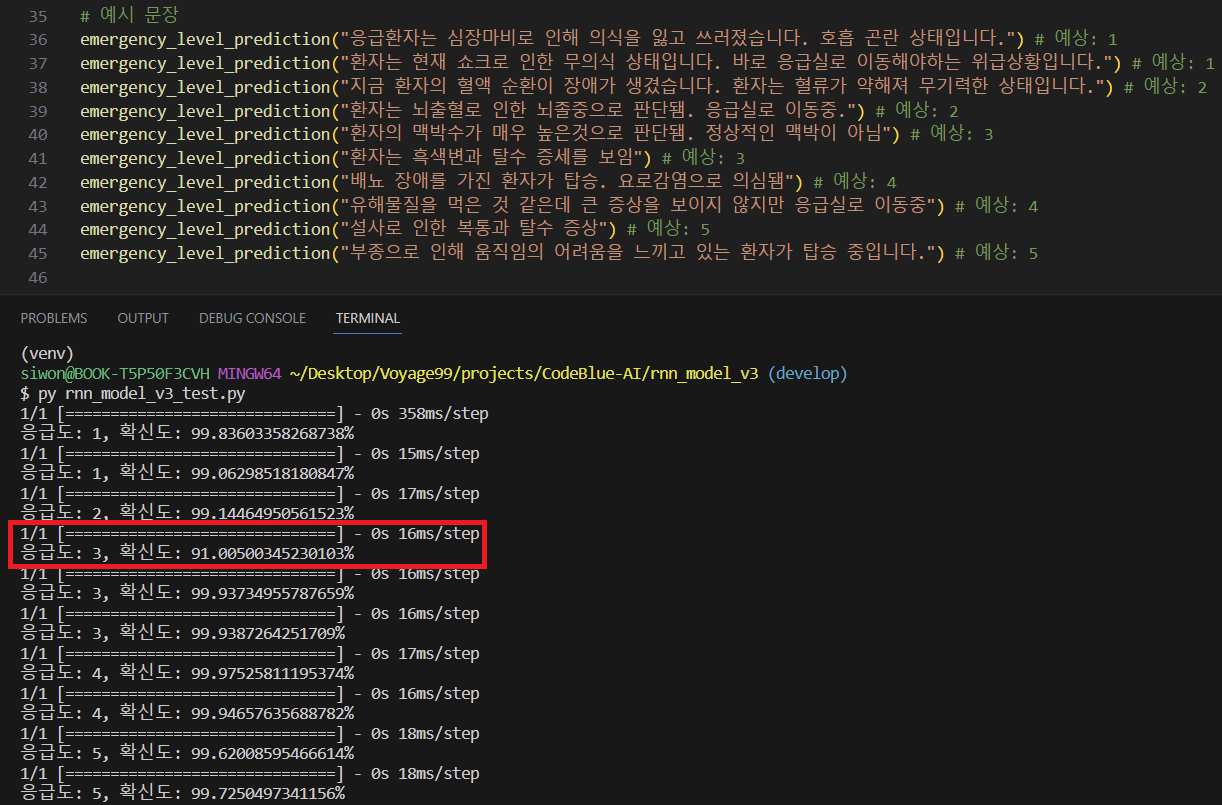
Compared to the accuracy of the initial model trained in Experiment 1 (accuracy: 0.927), the accuracy increased to 0.969. The acuity prediction also improved. However, there was a slight decrease in acuity prediction compared to Experiment 3. The confidence score also showed 91% accuracy in incorrectly predicted sentences.
![[코테] 그리디 문제 - 무지의 먹방 라이브](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1712215455263%2F1ac1f35a-8862-4e42-8d0c-e2bea01e04c0.png&w=3840&q=75)
![[코테] Bfs 토마토](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1709032619170%2F70056896-c857-444b-9c99-45bfcb466806.png&w=3840&q=75)
![[코테] Dfs 문제 유형 - 그래프 내에서 구분하여 카운트 하기](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1709019361383%2Fb0585d72-c808-4169-83a9-2724f312e927.png&w=3840&q=75)
![[코테] DFS vs BFS](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1708971211123%2F71f9386c-6a62-43b2-a602-4d084c24d6cf.png&w=3840&q=75)
![[코테] 여행경로](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1708971251412%2F27ce72ed-8ee7-4d13-a02f-ff4bbe50c4be.png&w=3840&q=75)