[TIL] AI Model - BERT
06/11/23
Published
![[TIL] AI Model - BERT](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1688369662521%2F32febd64-539c-4371-a3d5-f5752d296880.png&w=3840&q=75)
📌 What I did today
The necessity of BERT as a learning model
BERT is a learning model that takes an existing model and fine-tunes it to fit our needs. Fine-tuning is a technique where a pretrained model is updated to align with downstream tasks. Models trained with domain-specific data tend to perform better.
Selection of BERT huggingface transformers model
bert-base-multilingual-cased bert-base-multilingual-cased is a model specialized in over 100 languages, but it doesn't seem to have extensive training on the Korean language. The total number of Korean vocabulary it was trained on is 119,546.

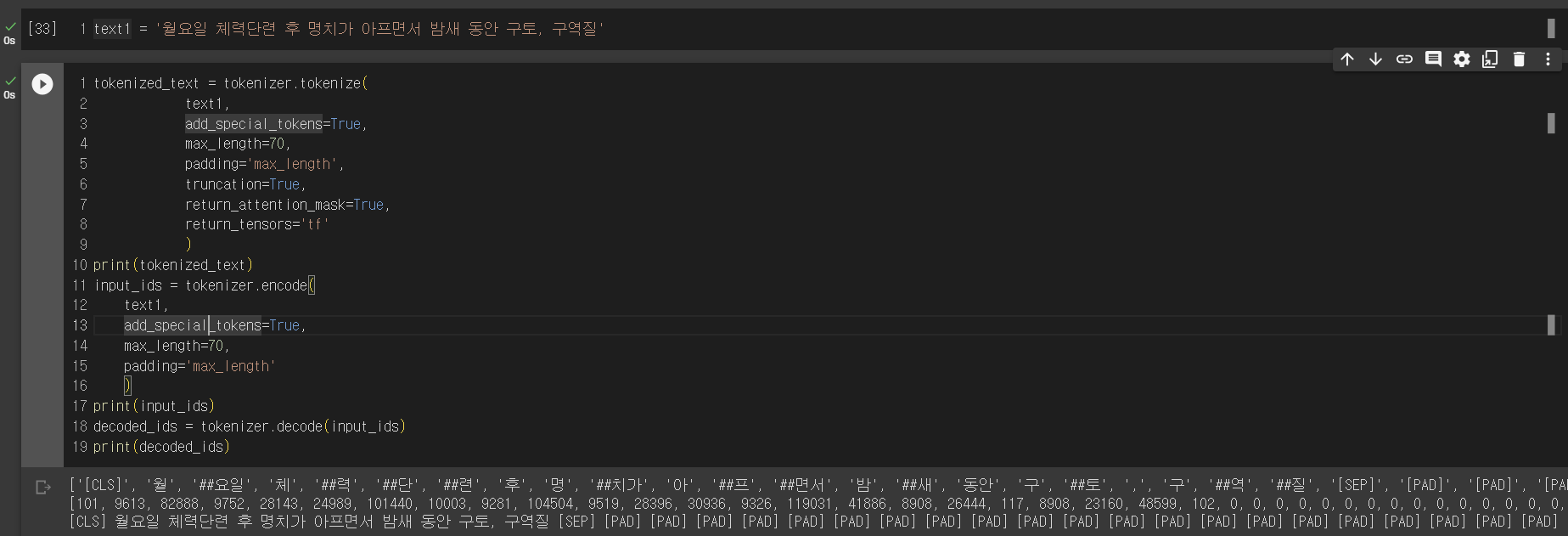
When using the raw tokenizer of BERT:
- KoBERT A model that overcomes the limitations of Google's bert-base-multilingual-cased for Korean language performance.
- Reference GitHub repositories: https://github.com/SKTBrain/KoBERT/tree/master/kobert_hf https://github.com/monologg/KoBERT-Transformers
\=> Selected KoBERT and currently implementing it.
AI training is really difficult... Feedback received during mentoring: accuracy >= 90!!! At least 90% accuracy is needed for meaningful free-text input.
![[코테] 그리디 문제 - 무지의 먹방 라이브](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1712215455263%2F1ac1f35a-8862-4e42-8d0c-e2bea01e04c0.png&w=3840&q=75)
![[코테] Bfs 토마토](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1709032619170%2F70056896-c857-444b-9c99-45bfcb466806.png&w=3840&q=75)
![[코테] Dfs 문제 유형 - 그래프 내에서 구분하여 카운트 하기](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1709019361383%2Fb0585d72-c808-4169-83a9-2724f312e927.png&w=3840&q=75)
![[코테] DFS vs BFS](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1708971211123%2F71f9386c-6a62-43b2-a602-4d084c24d6cf.png&w=3840&q=75)
![[코테] 여행경로](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1708971251412%2F27ce72ed-8ee7-4d13-a02f-ff4bbe50c4be.png&w=3840&q=75)