[TIL] Issues with NLP Model & What I Tried to Resolve them
06/13/23
![[TIL] Issues with NLP Model & What I Tried to Resolve them](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1688370047111%2F4bb30970-b1a5-4051-9150-c17d347bf32f.png&w=3840&q=75)
📌 What I did today
1. Model Training Visualization Tool: TensorBoard
In model training, important aspects are the resulting accuracy and the fluctuation of accuracy throughout each epoch. While the results were printed in the terminal for easy tracking, it had limitations without visualized graphs. Therefore, I used a tool called TensorBoard.
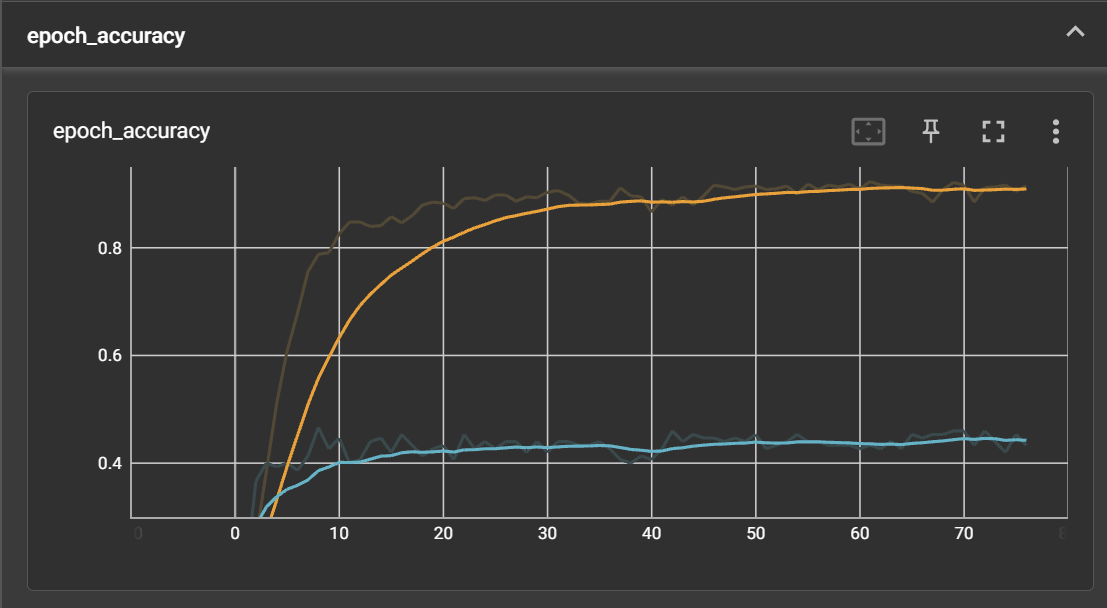
This allows us to visualize the accuracy trend. The orange line represents the accuracy for the training model, and the blue line represents the accuracy for the test model. Currently, I need to improve the accuracy of the test model. Even when changing the dataset and adjusting the hyperparameters, it remains around 0.4xx to 0.5.
2. Saving the Model Locally
from tensorflow.keras.models import load_model
# ...
# Load the existing model
model = load_model('rnn_model.h5')
# Compile the model (algorithm: adam, loss function: categorical_crossentropy, evaluation metric: accuracy)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Train the model (number of epochs: 1000, batch size: 32)
model.fit(X_train, y_train, epochs=1000, batch_size=32, validation_data=(X_test, y_test),
callbacks=[custom_early_stopping, lr_scheduler_callback, tensorboard_callback], verbose=1)
# ...
# Save the model
model.save('rnn_model.h5')
3. Testing Model Training by Changing Hyperparameters
Types of Hyperparameters
Hidden Layer Size: Using more hidden units allows the model to learn more complex patterns.
Dropout Rate: Dropout is a regularization technique used to prevent overfitting. Increasing the dropout rate allows more neurons to be deactivated.
Adding LSTM Layers: It is worth considering adding additional LSTM layers. For example, adding a second LSTM layer and adjusting the hidden layer size.
Adjusting Learning Rate Scheduling: Fine-tuning the learning rate scheduling can be done more finely. It can start with a smaller decay rate or decrease it after more epochs.
Using More Data: Collecting more normalized data and using it for training. The more data, the more diverse patterns the model can learn.
📌 Approach to Problem-solving
Problem Situation: Issue with the accuracy of the sentence learning model being stuck around 0.4xx to 0.5.
* Point 1: Is the RNN model we built working properly?
We have been training the model only on our own, unnormalized dataset. Therefore, we are not confident whether the model is working correctly.
* Point 2: Does the RNN model have an understanding of Korean sentences?
Even if we train the model with thousands to tens of thousands of datasets, the current model is not specifically trained on Korean sentences. It means that even with a slight change in a sentence, the model may not recognize it as a similar sentence to those it has been trained on.
* Point 3: Is the dataset normalized?
Since the topic is in the medical field and the dataset we want consists of symptom report sentences (1) and severity level data based on these sentences (2), such information is considered personal information and is not easily accessible for us to find. Therefore,
we used ChatGPT to generate several sentences in the format of symptom reports when given keywords related to patient symptoms, and asked for severity assessment based on the KTAS. We extracted about a thousand related data points. However, it is difficult to determine whether this dataset is properly normalized.
Facing the Problem + Mentoring Task Lists
Task 1
- Test the RNN model with a pre-built, normalized dataset by someone else to evaluate its performance (Determining Points 1 & 2).
Task 2
2-1. If the RNN model works well with the normalized dataset (sufficiently high accuracy) and our dataset is not properly normalized, invest more time in normalizing the dataset.
2-2. If the RNN model itself is problematic, consider changing the AI model to a fine-tuned one.
![[코테] 그리디 문제 - 무지의 먹방 라이브](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1712215455263%2F1ac1f35a-8862-4e42-8d0c-e2bea01e04c0.png&w=3840&q=75)
![[코테] Bfs 토마토](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1709032619170%2F70056896-c857-444b-9c99-45bfcb466806.png&w=3840&q=75)
![[코테] Dfs 문제 유형 - 그래프 내에서 구분하여 카운트 하기](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1709019361383%2Fb0585d72-c808-4169-83a9-2724f312e927.png&w=3840&q=75)
![[코테] DFS vs BFS](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1708971211123%2F71f9386c-6a62-43b2-a602-4d084c24d6cf.png&w=3840&q=75)
![[코테] 여행경로](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1708971251412%2F27ce72ed-8ee7-4d13-a02f-ff4bbe50c4be.png&w=3840&q=75)